Welcome to the world of Time Series Analysis and forecasting!!
1 Introduction.
There are two hands-on exercises planned for you in this workshop. The first one is on basic starting steps which we will do now and the other is at end of the workshop which is based on workflows. In this exercise, the participants have to follow the principles and practices as explained in the workshop so far. We have to do the following actions for completion of this exercise:
Create a new project titled “time_series” at a desired location in the computer.
Create folders named “data” and “scripts”.
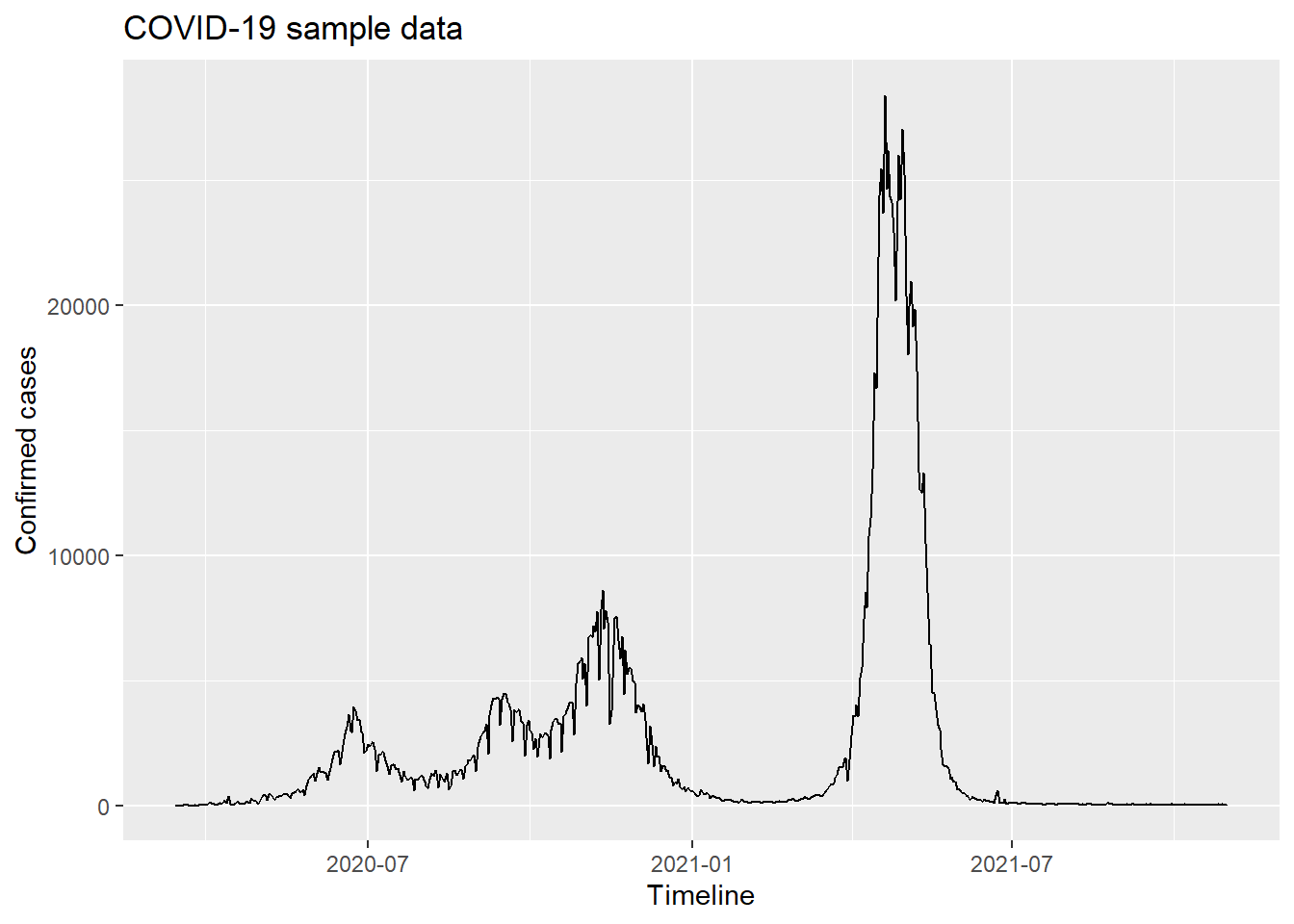
Copy the “covid_IPHACON2024.csv” file to the data folder.
Create a script and name it as “covid_analysis”.
Load libraries.
Load data.
Explore data
Calculate traditional statistics.
Create a time series object.
Tip
It is a good practice to always have a new project and dedicated folders for your independent research activities. It enables better database management especially when you are involved in multiple research activities. Project based approach is also helpful in better communication and sharing of the workflows.
2 Load libraries.
Once your project is ready with specified folders and files at right locations, working in modular fashion provides a more intuitive approach to your analysis. Let’s load libraries for working further.
library(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.2 ✔ readr 2.1.4
✔ forcats 1.0.0 ✔ stringr 1.5.0
✔ ggplot2 3.4.2 ✔ tibble 3.2.1
✔ lubridate 1.9.2 ✔ tidyr 1.3.0
✔ purrr 1.0.1
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
We should be careful in loading libraries. Loading unwarranted libraries and those which are going to be utilised only once or twice in the entire analysis is not a good habit as it unnecessarily burdens the system and compromises computational efficiency!
Now since we have created a time series object, lets move further.
Further exercises.
During the workshop, as we proceed, we shall be getting back to this exercise for calculating time series features and understanding concepts such as ACF, MAs, etc. Happy learning!